
반응형

비지도 학습이란
- 문제만 있고 정답은 없는 경우 사용하는 머신러닝 기법
- 군집화(Clustering)와 연관관계 분석이 대표적
- 군집화 : 데이터를 비슷한 유형별로 묶음
- 연관관계 분석 : 데이터 간 연관 규칙을 파악
분류(Classification)와 군집(Clustering)의 차이는?
라벨(정답)의 유무
분류는 라벨이 있지만 군집은 라벨이 없다.
군집화 알고리즘
잘된 군집화
- 동일한 군집의 데이터들은 서로 유사할수록 좋음 (High intra-cluster similarity)
- 다른 군집에 속한 데이터들은 서로 다를수록 좋음 (Low inter-cluster similarity)
K-평균 군집화(K-means Clustering)
- 대표적인 분할적 군집화 알고리즘
- 사전에 군집 수(K)를 지정
- 각 군집은 하나의 중심점이 존재
- 초기 중심점의 영향을 받는다
K-평균 군집화 절차
- 구하고자 하는 군집의 수(K)를 설정
- K개의 중심점 임의 지정
- 각 데이터로부터 중심점까지 거리 계산해 데이터들을 가장 가까운 중심점이 속한 군집으로 할당
- 중심점을 해당 군집에 할당된 데이터들의 평균위치로 갱신
- 중심점이 변경되지 않을 때까지 2, 3 과정을 반복
군집화 결과 평가
- 실루엣 계수(Silhouette coefficient)로 평가
- a(i) : 클러스터 내의 응집이 덜된 정도
- b(i) : 클러스터 간의 분리도
- -1에 가까울수록 나쁜 결과이고 1에 가까울수록 좋은 결과
- 가장 이상적일 때(클러스터가 한 점) : a(i) = 0, 실루엣지표 = 1
- 최악의 경우(인근 클러스터와 한 점) : b(i) = 0, 실루엣지표 = -1
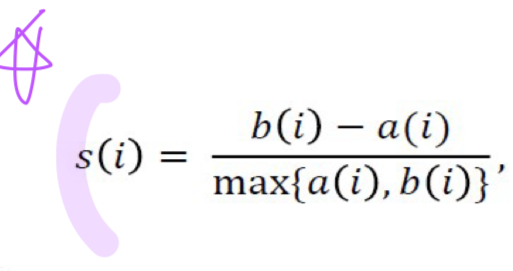
군집의 개수(K)의 설정
- 평가 지표를 이용하여 최적의 군집 수 선택
- Elbow point
- X축 : 클러스터 개수
- Y축 : 클러스터 내 SSE
군집 개수(K)에 따른 SSE
- K가 증가할수록 SSE 감소
- K가 데이터 개수와 같아지면 SSE는 최소(0)
- 무조건 SSE값이 작다고 좋은게 아닌 큰 폭으로 감소할 때가 좋음
장단점
- 장점
- 알고리즘이 단순하고 빠름
- 단점
- 클러스터 개수(K)의 따라 결과가 크게 달라짐
- 아웃라이어에 취약
연관분석 (Association Analysis)
아이템과 아이템 간의 상호 관계나 종속 관계를 찾아내는 분석 방법
연관규칙을 찾기 위한 지표
- 신뢰도(Confidence)
- X → Y의 신뢰도란 X를 포함하는 거래 내역 중 Y가 포함된 비율
- 방향이 중요 → 의미가 다르기 때문
- X 물품 구매 고객이 Y물품 구매 확률
- 지지도(Support)
- 전체 구매 건 중 차지하는 비율
- 빈도가 높은 조합을 찾기 위함(빈도 낮음 의미가 없기에)
- 전체 대비 X와 Y가 함께 구매된 비율
- 향상도(Lift)
- 그냥 Y를 구매할 때 대비, X를 구매하고 Y를 구매할 확률 증가 비율
- 일반적으로 향상도가 1이상일 때 의미
- 향상도 = 1 : X와 Y는 독립
- 향상도 < 1 : X를 구매하면 Y를 구매하지 않을 확률이 구매할 확률보다 큼
- 향상도 > 1 : 임의로 Y를 구매할 확률보다 X를 구매할 때 Y를 구매할 확률이 큼
- 사용 방법
- 향상도는 의미있 조합을 골라내기 위해
- 지지도는 빈도가 낮은 상품을 버리기 위해
- 지지도 기준으로 필터링 후 신뢰도와 향상도로 선별
반응형
'AI&Data' 카테고리의 다른 글
| 데카르트 발표 공유용 (0) | 2025.04.15 |
|---|---|
| 데이터 사이언스 [Data Science] - HR - 모델링(선형회귀, 램덤포레스트, Sequential) (1) | 2024.12.28 |
| 머신러닝[Machine Learning] - 선형회귀(Linear Regression) (0) | 2024.12.05 |
| 데이터 사이언스 [Data Science] - HR - 전처리(인코딩 및 스케일링) (4) | 2024.11.30 |
| 데이터 사이언스 [Data Science] - HR - EDA(탐색적 데이터 분석) (0) | 2024.11.29 |