반응형
Remind
이전 글에서 EDA 작업을 통해 데이터를 분석하였다.
이번에는 데이터 전처리 작업을 진행해보려고 한다.
데이터 사이언스 [Data Science] - HR - EDA(탐색적 데이터 분석)
Remind이전 글에서 HR 도메인 지식을 정리하고 모델링 구축을 계획했다.모델링에 앞서 데이터를 이해하고 문제 해결을 위한 가설을 형성하기 위해 EDA 작업이 필요하다. 데이터 사이언스 [Data Scienc
daino.tistory.com
인코딩
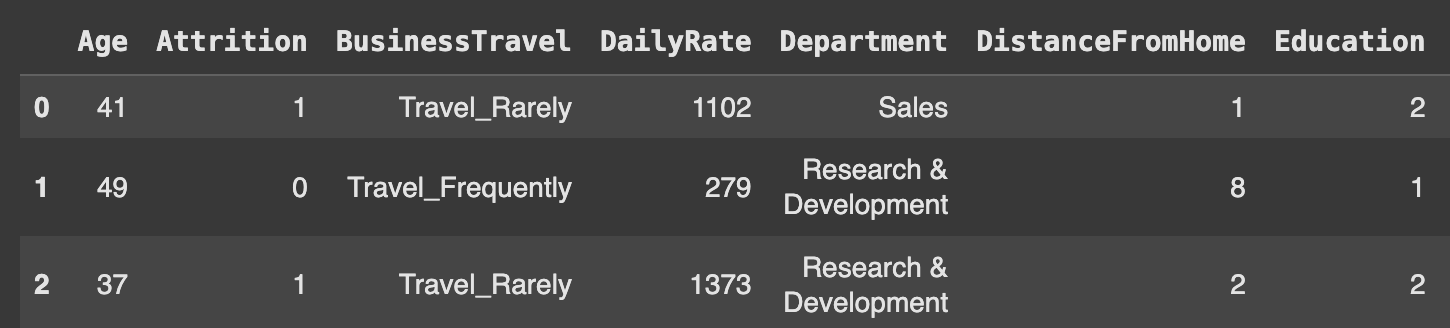
데이터 샘플 확인
- 데이터를 살펴보면 범주형 데이터와 수치형 데이터가 혼합된 것을 알 수 있다
범주형 vs 숫자형
범주형 : 특정 그룹이나 범주를 나타내는 데이터
숫자형 : 숫자로 표현되며, 계산 가능한 데이터
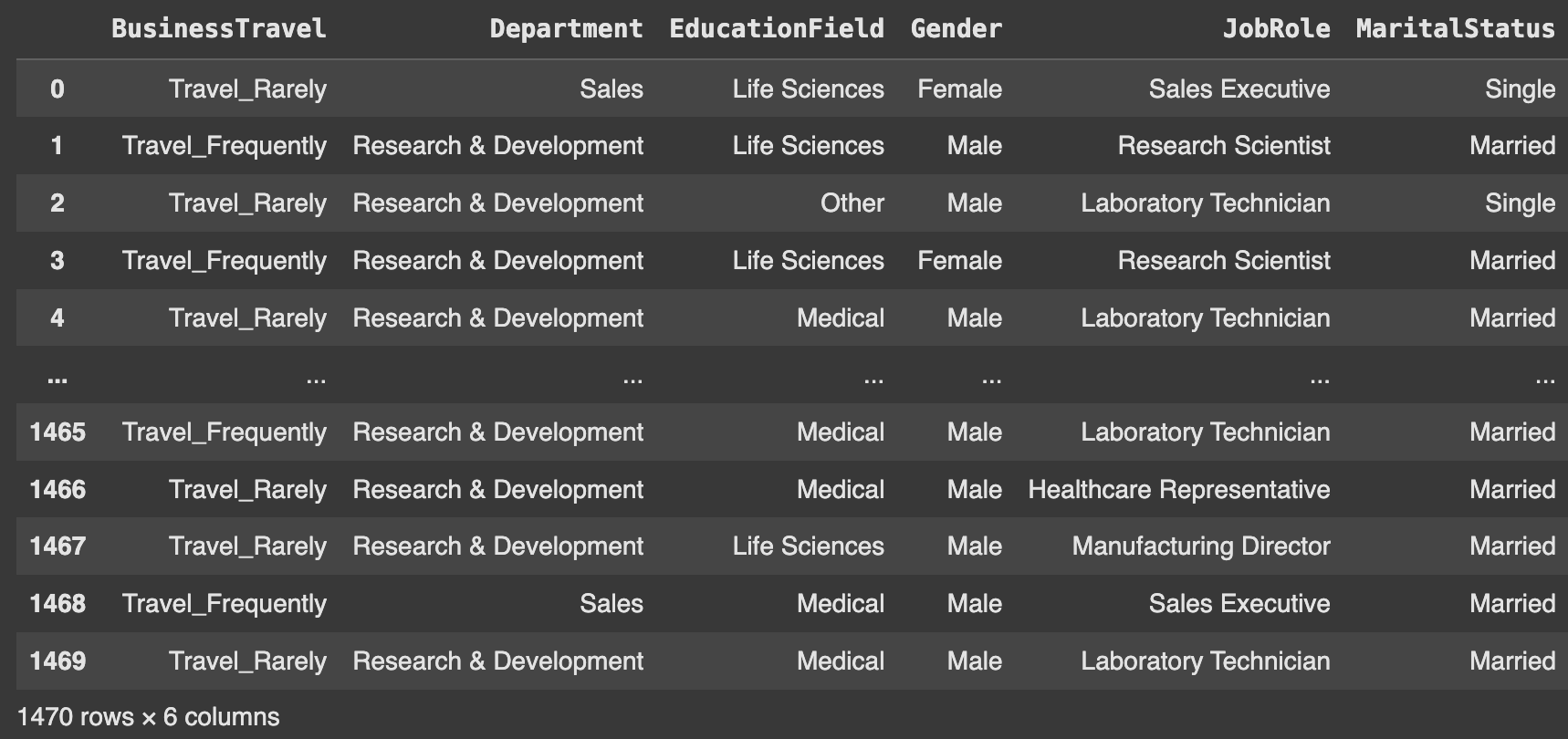
범주형 데이터 분리
- 범주형 데이터는 인코딩을 하여야 머신러닝 모델에 사용 가능
- 범주형 데이터 인코딩을 위해 데이터프레임 분리
X_cat = employee_df[['BusinessTravel', 'Department', 'EducationField', 'Gender', 'JobRole', 'MaritalStatus']]
OneHotEncoder를 사용하여 인코딩
인코딩이란?
데이터를 컴퓨터가 처리할 수 있는 형식으로 변환하는 과정
주로 범주형 데이터를 숫자형 데이터로 변환하는 데 사용
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder()
X_cat = onehotencoder.fit_transform(X_cat).toarray()
인코딩된 값을 Dataframe으로 변경
- 인코딩시 이진 벡터로 변경되기에 다시 Dataframe으로 변경해줘야 함
X_cat = pd.DataFrame(X_cat)
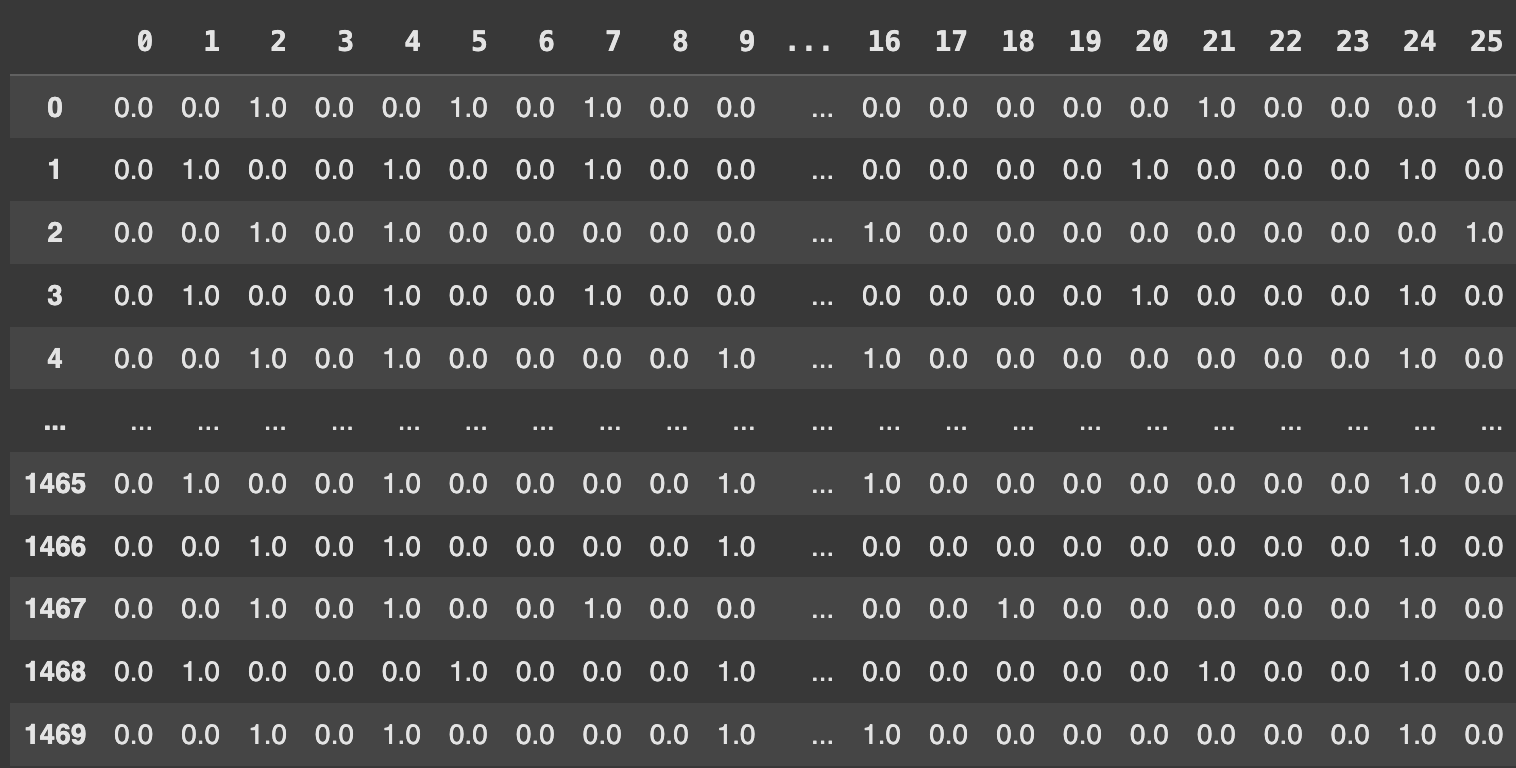
숫자형 데이터와 결합
- 같은 방법으로 원본 데이터 프레임에서 숫자형 데이터 분리
- concat 매서드를 이용해 숫자형 데이터와 범주형 데이터 연결
X_numerical = employee_df[['Age', 'DailyRate', 'DistanceFromHome', 'Education', 'EnvironmentSatisfaction', 'HourlyRate', 'JobInvolvement', 'JobLevel', 'JobSatisfaction', 'MonthlyIncome', 'MonthlyRate', 'NumCompaniesWorked', 'OverTime', 'PercentSalaryHike', 'PerformanceRating', 'RelationshipSatisfaction', 'StockOptionLevel', 'TotalWorkingYears' ,'TrainingTimesLastYear' , 'WorkLifeBalance', 'YearsAtCompany' ,'YearsInCurrentRole', 'YearsSinceLastPromotion', 'YearsWithCurrManager']]
X_all = pd.concat([X_cat, X_numerical], axis = 1)
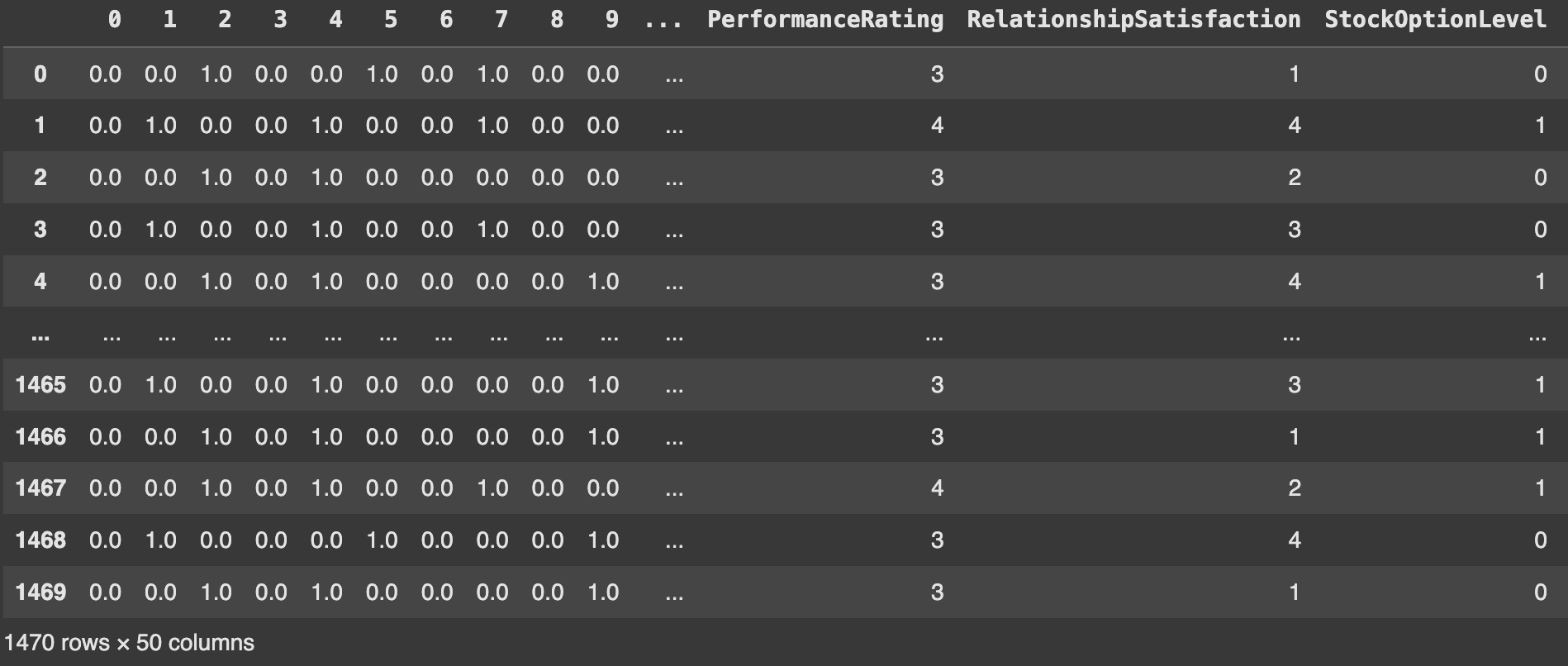
칼럼명 타입 변환
- 인코딩 작업 시 칼럼명이 int 타입으로 변환됨
X_all.columns.map(type)
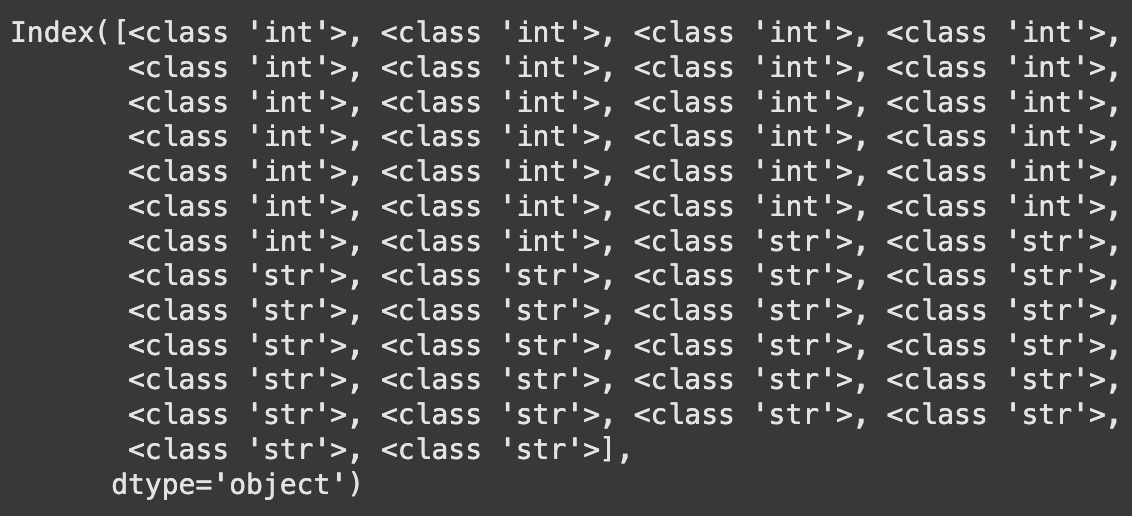
- 칼럼명의 타입을 문자형으로 전부 변환
X_all.columns = X_all.columns.astype(str)
스케일링
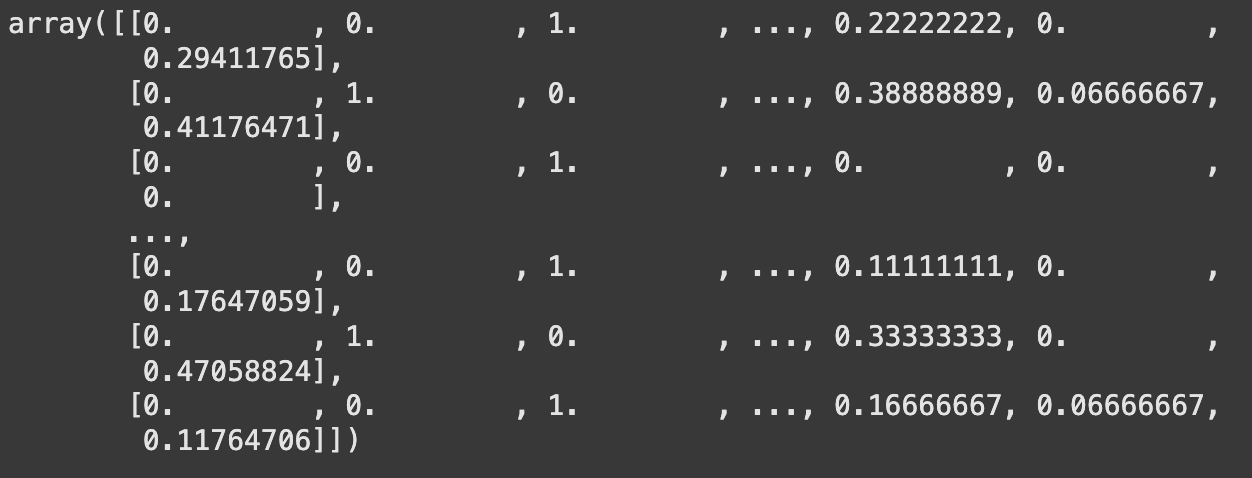
- 변수 간의 범위가 달라 스케일링이 필요
스케일링을 하는 이유는?
각 특성 값의 범위가 다르면 모델 학습에 영향을 줄 수 있기 때문에 값의 범위 차를 줄여주는 작업 필요
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X = scaler.fit_transform(X_all)
종속변수 분리
- 예측하고 싶은 퇴사여부 y값으로 분리
y = employee_df['Attrition']
모델링 과정 보러가기
데이터 사이언스 [Data Science] - HR - 모델링(선형회귀, 램덤포레스트, 인공신경망)
Remind 이전 글에서 모델링 적합을 위해 데이터 전처리를 진행해 줬다.이번 글에는 본격적으로 모델링 작업을 해보려 한다. 데이터 사이언스 [Data Science] - HR - 전처리(인코딩 및 스케일링)Remind이
daino.tistory.com
반응형
'AI&Data' 카테고리의 다른 글
| 머신러닝[Machine Learning] - 비지도학습 (1) | 2024.12.05 |
|---|---|
| 머신러닝[Machine Learning] - 선형회귀(Linear Regression) (0) | 2024.12.05 |
| 데이터 사이언스 [Data Science] - HR - EDA(탐색적 데이터 분석) (0) | 2024.11.29 |
| 데이터 사이언스 [Data Science] - HR - 비즈니스 사례 이해 및 모델 구축 계획 (1) | 2024.11.28 |
| [Teachable Machine] 학습태도 및 성향관찰 분석 모델링 (0) | 2024.09.14 |